
It was a Tuesday. Three months into building the automation stack — the VPS configuration, the SSH hop pattern through Tailscale, the credential vault architecture, the naming conventions that took two weeks to settle on. I opened a new session and described what I needed to do next.
Claude said: “I don’t have context on that setup. Could you walk me through it?”
Not a crash. Not an error message. Just a polite, blank stare. Three months of accumulated decisions — gone. Not because the model failed. Not because my internet dropped. But because there was simply nowhere for it to live between sessions.
That moment has a name: the persistent memory problem. And in 2026, every developer building production AI agents hits it eventually, and yes most LLMs now have a basic memory store built in; it’s just “ok.”
Now you build a prototype. The demo is clean. The AI feels like a collaborator. Then it runs in the real world for a few weeks, and a gap opens up between what the model can do and what it actually remembers.
But this article isn’t really about that technical gap. That gap is well-documented. Benchmarked. Actively researched. There’s an entire ecosystem of memory frameworks building toward solutions.
This article is about the part nobody is talking about: what happens to your memory when it does get stored. Who holds it. Who profits from it. What you can’t take with you when you leave. And why the AI industry has structurally designed a system where your knowledge — the context you’ve spent months building — is simultaneously your most valuable asset and one you have almost no rights over.
The AI that knows you best is almost certainly owned by someone else. And they have very specific plans for what you’ve told it.
We’ll get to the technical solutions. But first, let’s understand exactly what’s happening with your data right now — because most people who use AI daily have no idea.
The AI agents market was valued at $7.84 billion in 2025 and is projected to reach $52.62 billion by 2030 — a 46.3% compound annual growth rate. Gartner estimates 40% of enterprise applications will be integrated with task-specific AI agents by end of 2026. IDC puts AI copilots inside 80% of enterprise workplace tools by the same date.
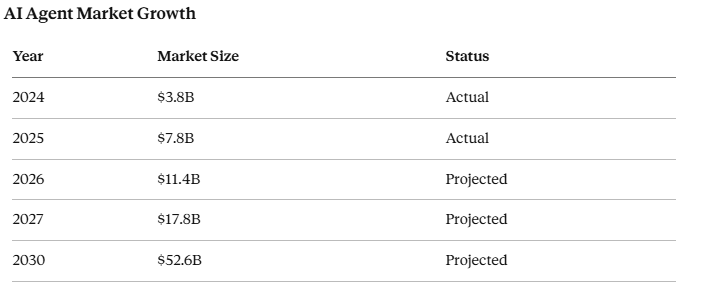
Three numbers that define the gap:
The gap between broad adoption and genuine impact is enormous. Much of it comes down to one unsolved problem: agents that don’t retain what they learn. And the memory layer — the piece that would close that gap — is where your data lives, moves, and gets used in ways you almost certainly haven’t read about.
Let’s be specific. Because this is the section most AI commentary skips, or buries in caveats, or softens with “but they have good intentions.” We’re not going to do that.
Here is what is actually happening to your conversations right now, provider by provider, tier by tier.
ChatGPT — Free / Plus / Pro (Consumer)
ChatGPT — Team / Enterprise
Claude — Free / Pro / Max (Consumer)
Claude — API / Claude Code
Gemini — Free / AI Pro / Ultra (Consumer)
Gemini — Google Workspace (Enterprise)
Meta AI — All Tiers
Sources: Anthropic Privacy Center, OpenAI Privacy Policy, Google Gemini Privacy Hub, drainpipe.io (2026), Incogni LLM Privacy Ranking (2025–2026), AxSentinel Data Retention Report (2026)
Critical — Claude Pro Users
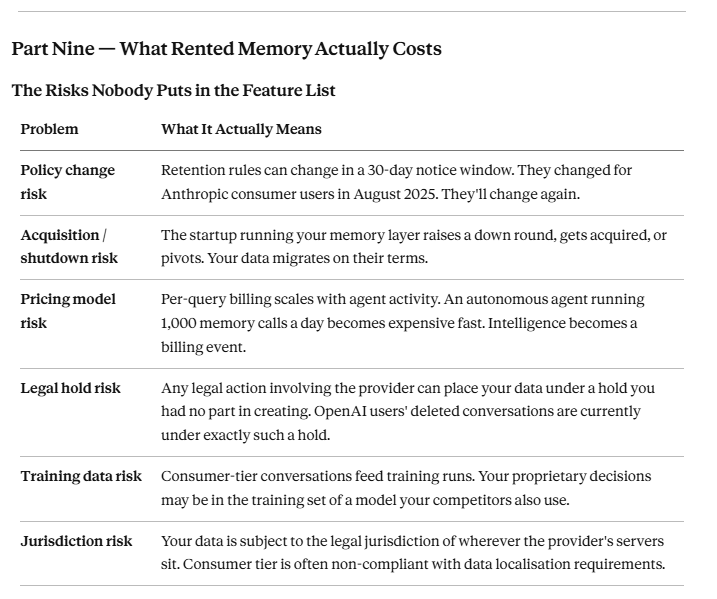
If you use Claude Pro for client work or sensitive projects and have not manually opted out of training in Settings → Privacy → “Improve Claude for everyone,” your conversations are being retained for up to five years and used to train future models. The opt-out toggle defaulted to On. If you clicked Accept without adjusting it, you opted in. Turning it off now does not retroactively remove data already used for training.
The OpenAI court order deserves its own paragraph because it’s genuinely alarming. In 2025, a court order arising from the New York Times lawsuit forced OpenAI to retain all consumer ChatGPT conversations indefinitely — including conversations users had already deleted. A single data breach in 2025 exposed approximately 300 million AI chat messages. Stanford researchers flagged indefinite retention as a systemic risk. And the industry continued shipping features.
When you delete a conversation, it stays on OpenAI’s servers indefinitely — because a court said so, and there’s nothing you can do about it.
The business model is not complicated: consumer data funds training runs that make the enterprise product better. Enterprise customers pay for the improved model. Consumer users are both the customer and the product.
Between February 2024 and March 2026, ChatGPT, Claude, and Gemini all transitioned from stateless chatbots to systems that retain long-term personal context by default. For most of that period, that memory was locked. The longer you used any one platform, the more it knew about you, and the more expensive switching became — not in money, but in context.

The March 2026 portability scramble is instructive about how this industry works. Three companies shipped memory export and import capabilities within a 30-day window — not because they decided it was the right thing to do, but because EU GDPR Article 20 compliance deadlines forced them to.
And what actually transfers? Explicit stored facts — your name, job, location. Stated preferences. But not the structured memory that makes your AI actually useful. Not the trained preferences and behavioral patterns built from thousands of interactions.
Exporting raw transcripts is not the same as exporting portable, usable context. The memory that makes your AI useful is typically locked inside the vendor’s proprietary format. — XTrace AI, Vendor Lock-In Analysis (2026)
McKinsey published a major analysis in 2026 on sovereign AI — the idea that nations and organisations need to control their own AI infrastructure, data, and compute, to avoid becoming permanently dependent on whoever does. France is rebuilding its entire cloud provider stack. The EU is treating AI sovereignty as economic security on par with energy independence.
McKinsey estimates €480 billion in annual GDP impact from sovereign AI solutions in Europe alone by end of decade. Their analysts identified three urgency drivers:
If a government depending on foreign AI infrastructure has a sovereignty problem — what do you call it when your entire professional context lives on someone else’s server, subject to their policies, their training decisions, their survival as a company?
The academic literature is catching up. A 2025 paper from the University of Zagreb introduced “cognitive sovereignty” — the ability of individuals to maintain autonomous thought and preserve identity in the age of AI systems that hold deep personal memory. UC Berkeley and Google DeepMind published the Opal paper in April 2026 — a technical architecture for genuinely private personal AI memory using cryptographic primitives. Tim Berners-Lee’s Solid project is building personal data pods independent from applications.
Building a production AI agent system over several months generates a specific kind of accumulated context. Not just code — decisions. Why you structured things the way you did. Why certain conventions exist. The technical debt you decided to live with, and why.
One recurring example: the keyName vs keyPath distinction in SSH tooling. Session after session, a fresh Claude instance would default to keyPath. You’d correct it to keyName. It would work. Session would end. Next session: same default. Same correction.
The model wasn’t forgetting — it never knew in the first place. The convention existed in the codebase, but the reason for it lived nowhere the model could reach. The human became the memory layer. Three months of architectural decisions, stored in a human brain, re-entered by hand every time the context window reset.
You were paying $20 a month to train a model on your proprietary decision-making process.
The Real Cost Calculation
What you think you’re paying for: Faster, smarter AI assistance on your projects.
What’s also happening: Your architectural decisions, debugging sessions, and proprietary context are being retained for up to five years and used to train the future model that your competitors also use — unless you explicitly opted out before September 28, 2025.
Zero-day reality: Turning off training now does not remove data already ingested into training runs.
The AI agent memory research community has converged on a framework: four distinct dimensions that a complete memory layer handles simultaneously. Storage, curation, retrieval, and lifecycle. Viewed through the lens of sovereignty, each becomes an ownership question.
01 — Storage: Where does your memory live? On vendor cloud infrastructure. You access it through their API. Their uptime. Their pricing. Their terms. Their jurisdiction. A policy memo can change all of that.
02 — Curation: Who decides what gets kept? Their algorithm, trained on aggregate behaviour. What matters to you may not match what their system weights. Contradictions accumulate. Noise builds. Retrieval quality degrades over months.
03 — Retrieval: Who controls what surfaces? Their vector index, their ranking, their server. A cloud outage or pricing change can make your memory inaccessible on the day you need it most.
04 — Lifecycle: Who decides when it expires? Their policy team. Anthropic changed consumer retention from 30 days to 5 years in one policy update. You had 28 days to notice and opt out.
The ECAI 2025 benchmark paper is the most rigorous public evaluation of memory approaches — testing ten different architectures against the LOCOMO dataset. The results reveal where the real gaps are:
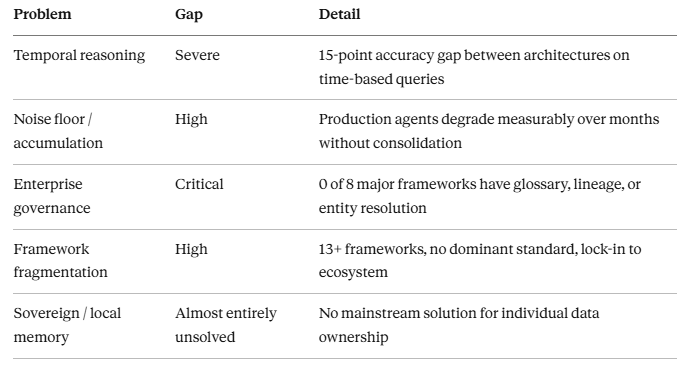
The temporal reasoning gap is particularly significant. There’s a 15-point accuracy difference between architectures on time-based queries because pure vector similarity is structurally incapable of answering “what did the agent know last Tuesday?”
The noise floor problem catches people in production. A memory system that appends without consolidating is fine for a week. After six months, retrieval quality degrades as the agent surfaces conflicting beliefs about the same subject. The research term for this is “memory pollution” — your AI’s context becomes less reliable the more it knows, if consolidation is absent.
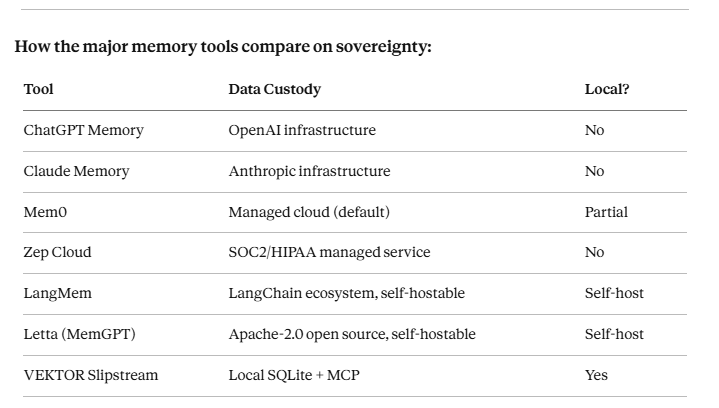
The problems in the previous section aren’t bugs — they’re structural features of cloud-hosted memory. The only way to not have those problems is to not be on cloud-hosted memory.
The architecture that solves the sovereignty problems:
The sovereign AI conversation is happening at scale. France is spending billions to not depend on American cloud infrastructure. The EU is treating AI memory and data sovereignty as economic policy. At the enterprise level, companies are paying serious money to keep their data out of training pipelines.
At the individual level — the developer, the freelancer, the solo founder, the professional who has spent months building AI-assisted context — the conversation hasn’t started yet. The default is: cloud, training opt-in, multi-year retention, per-query billing, vendor-coupled memory, and policy terms that can change with a 30-day notice.
The research — the ECAI benchmarks, the Brcic “Memory Wars” paper on cognitive sovereignty, the Opal system from UC Berkeley, Tim Berners-Lee’s Solid project — is pointing toward the same architecture: memory that individuals control, stored in formats that aren’t proprietary, encrypted with keys that don’t leave the device, accessible by any model through open protocols.
The AI that knows you best should be the one you own. The rest is tenancy.
Your memories are not a side effect of using AI. They’re the accumulated intelligence of your professional practice, your decision-making, your intellectual work. The question of who holds them, who profits from them, and who can revoke access to them is not a settings question. It’s a strategic one.
Sovereign AI is national policy now. Personal sovereign memory is still mostly an unsolved problem the market hasn’t priced in. That gap won’t stay empty for long.
Vektor Slipstream — local-first intelligent memory for AI agents. SQLite-native, MCP-compatible, AES-256 encrypted. vektormemory.com